JaVi v0.8 - Java Vigenere 1. Introduction 2. The JaVi GUI 3.1. The Vigenere's algorithm 2. A taste of statistics 4.1. The classes 2. UML stuff 5. Problems and known bugs 6. Ideas for the future
1. Introduction 2. The JaVi GUI (Graphical User Interface) 3. Vigenere's algorithm
"Approfondimento sulla crittografia" (in italian!), or use a search engine with keywords e.g. "Vigenere algorithm".
Anyway, briefly, the algorithm is based on the sum modulo n letter by letter of numbers associated at every character (in this case the Unicode numbers).
3.2. A taste of statistics
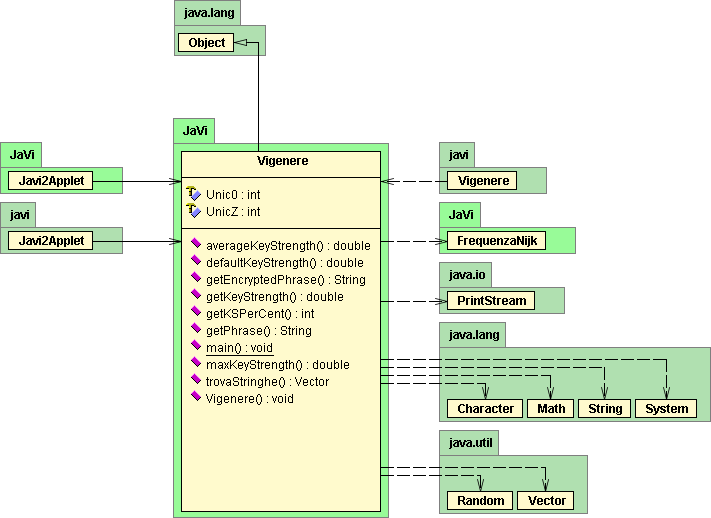
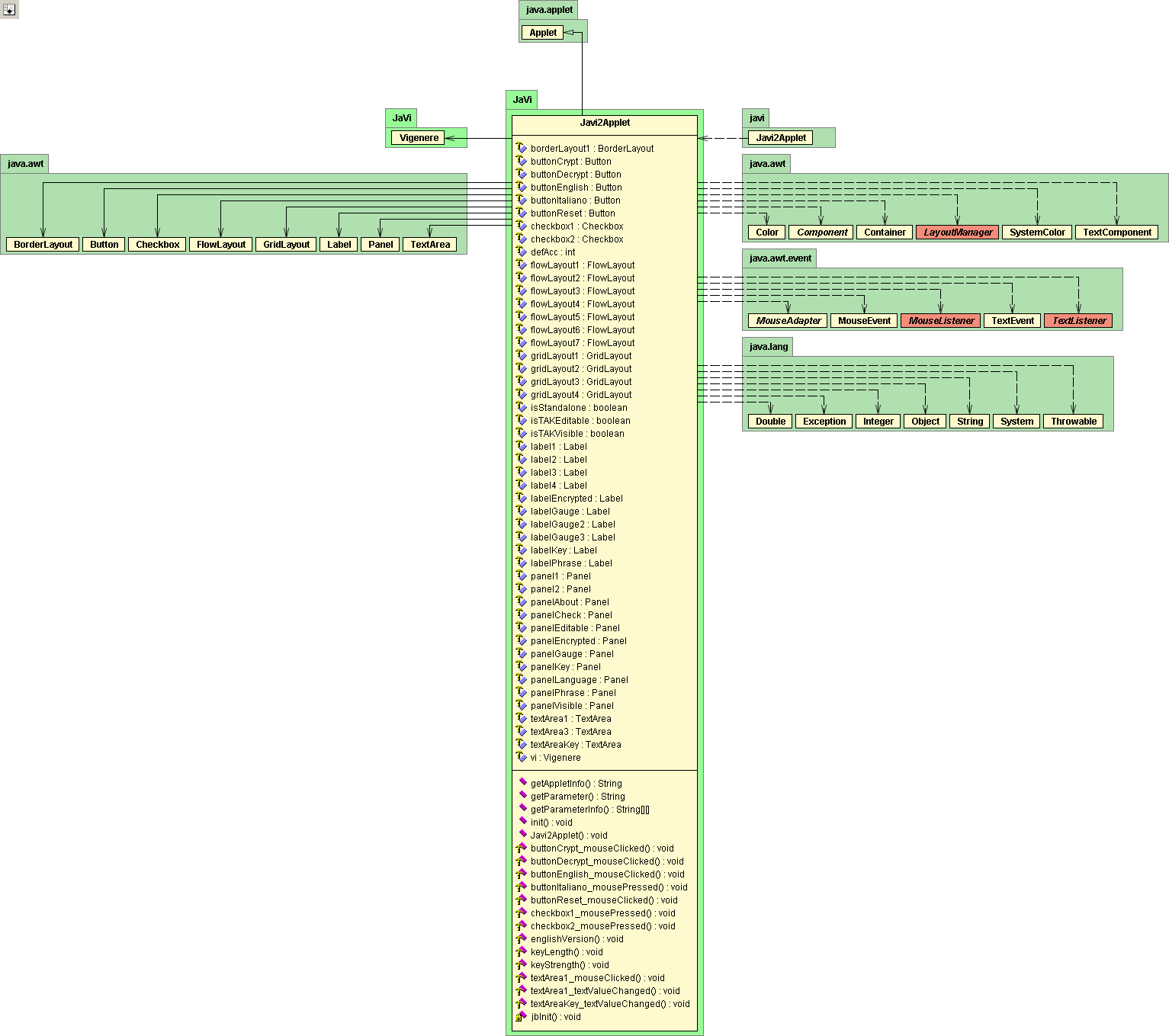
4.1. The classes.
www.unicode.org
4.2 UML diagrams. UML links 5. Problems and known bugs.
this form ,
including a brief description of the problem and of the platform on which the applet has run (processor, operating system (with version) and browser (with version)).
6. Ideas for the future
standalone application , beside of the applet version. If someone would like to contribute in the developing, I'd be glad to know about it.
Tell me about it .
Index of documentation




 5. Problems and known bugs.
5. Problems and known bugs.